Pagerank voor afbeeldingen in de maak

pagerank-voor-afbeeldingen-in-de-maak.jpg
In Peking werd vorige week tijdens het International World Wide Web Conference door Google researchers een soort PageRank voor Afbeeldingen gepresenteerd. Deze zoekmethode krijgt in de New York Times de term ‘VisualRank’ mee, Google zelf heeft het voorlopig over Image Rank. Image (of Visual dus) Rank is een algoritme die verschillende image-recognition software en technieken voor het waarderen van afbeeldingen samenvoegt.
Image Rank moet een enorme verbetering zijn voor het vinden van relevante afbeeldingen. Op dit moment wordt vaak alleen gebruik gemaakt van tekstuele eigenschappen die aan afbeeldingen zijn toegevoegd. Image Rank voegt technieken als face-detection en het filteren van objecten samen waardoor het veel efficiënter wordt. “We wanted to incorporate all of the stuff that is happening in computer vision and put it in a Web framework” zegt Shumeet Baluja van Google in de New York Times.
De werkwijze wordt uitgelegd in een pdf met de titel “PageRank for Product Image Search”. Het is niet eenvoudig uit te leggen, maar in basis werkt het zo dat een selectie van afbeeldingen, gemaakt via de ‘gewone’ zoekmethodes, wordt geanalyseerd. Door middel van speciale software wordt herkent welke afbeeldingen op elkaar lijken. Daarna worden ‘visuele hyperlinks’ geschat om een ranking te krijgen. Dit zijn geen ‘echte’ links, maar virtuele links die geschat worden. Hoe meer afbeeldingen op elkaar lijken, hoe meer geschatte links die krijgen. De afbeeldingen met de meeste inkomende links (linkto) ranken vervolgens het hoogste.
De Google Researchers die Image Rank ontwikkelden focusten zich eerst op de 2000 meest populaire product-searches op Google zoals iPod en Xbox. Hierna filterden ze de tien belangrijkste eruit op dezelfde manier zoals dat nu gebeurt bij Google Images. Op basis daarvan creëerden ze een systeem waarmee relevantie aan de afbeeldingen werd toegevoegd. Het toevoegen van ‘Image Rank’ leverde 83 procent minder irrelevante afbeeldingen op. Een tabelletje in het rapport verteld ons dat bij Image Rank binnen de top tien resultaten 0,47 afbeeldingen irrelevant waren, terwijl bij een ‘gewone’ search in Google 2,82 afbeeldingen van de tien irrelevant waren.

-391.jpg
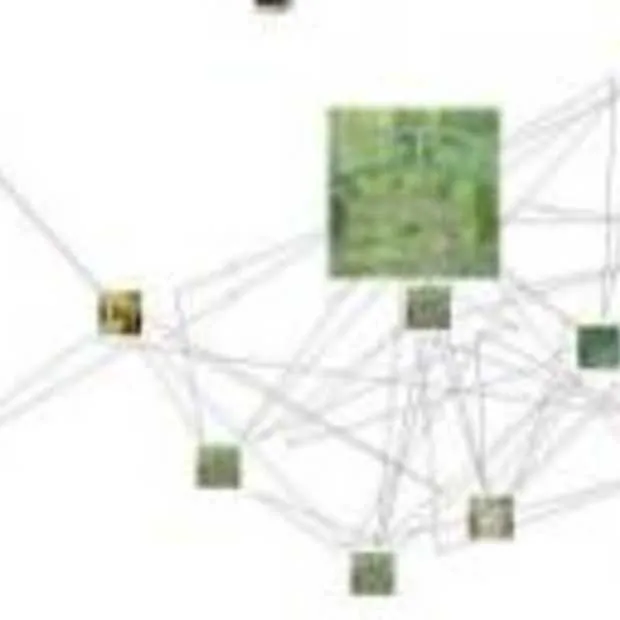
Bovenstaande afbeelding uit het rapport geeft een overzicht van de top 1000 resultaten op de zoekterm “Mona Lisa”. Hoe groter het plaatje, hoe hoger de ranking. De lijnen tussen de afbeeldingen geven de ‘virtuele links’ aan.
In 2006 werd een soortgelijk initiatief gelanceerd in de vorm van Like.com. De makers van die technieken zijn sceptisch over het succes van de Google-variant. Zij zeggen onder meer: “I think what they’re trying to accomplish is largely impossible. Our belief is, there is not large-scale solutions.”
Aangezien de Image Rank zoals Google die nu ontwikkeld heeft slechts op een deel van de geïndexeerde afbeeldingen van Google is uitgevoerd, omdat het niet ‘praktisch’ zou zijn om dit in de uitgevoerde test voor alle afbeeldingen te doen, kunnen ze daar best een punt in hebben.
Voor meer achtergronden hierover kan je de pdf downloaden of terecht op de volgende pagina’s:
New York Times
Search Engine Land
Techcrunch
New York Times
Search Engine Land
Techcrunch




Deel dit bericht
Loading